- Published on
Automating the Binding Process in Cython, Part 2
- Authors

- Name
- Kevin Givens
Part 2, Overview
Welcome back. In the previous post, I discussed generating pxd files (Cython C-level declarations) from C header files using pycparser. In this post, I want to explore using Cython's own parser to generate the corresponding Python wrapper classes and functions in a pyx files. As always, you can find the companion code to this post on my github page.
Using Cython's Parser
As a reminder from the last post, we are generating Python bindings for a C implementation of a trie data structure from the c-algorithms library (Incidentally, code from this same library is used as an example in the official Cython documentation. There's a lot of overlap between that documentation of some of the topics discussed here).
Cython's parser in written in Python. It's fairly straight-forward to use, though not terribly well documented. As with any conventional parser, each Cython declaration is represented as a node in an abstract syntax tree. The parser reads Cython code in pyx, pxd, or pxi files and generates C code that implements the CPython API.
Our approach, borrowed from the autowrap project, is to use Cython's pxd reading capabilities to generate pyx files. After all, for most Cython projects, one tries to maintain some type of consistent standard when implementing wrapper functions and classes. Using a parser just implements these standards automatically.
Compiler Pipeline
Now for some code. Cython's pxd parser can be accessed programatically. In the snippet below, we parse a pxd file from the command line and return an AST.
from Cython.Compiler.CmdLine import parse_command_line
from Cython.Compiler.Main import create_default_resultobj, CompilationSource
from Cython.Compiler import Pipeline
from Cython.Compiler.Scanning import FileSourceDescriptor
def parse_pxd_file(path):
options, sources = parse_command_line(["", path])
path = os.path.abspath(path)
basename = os.path.basename(path)
name, ext = os.path.splitext(basename)
source_desc = FileSourceDescriptor(path, basename)
source = CompilationSource(source_desc, name, os.getcwd())
result = create_default_resultobj(source, options)
context = options.create_context()
pipeline = Pipeline.create_pyx_pipeline(context, options, result)
context.setup_errors(options, result)
# root of the AST/parse tree
root = pipeline[0](source)
We use the function parse_command_line to pass the source code located at path to the Cython compiler with no compiler flags turned on. We then create a pxy compiler Pipeline from a CompilationSource objects and a default options context.
This pipeline is like a regular compiler pipeline through which phases of data transformation and optimizations occur. For our purposes, we will just walk the AST starting from the root node.
Parsing our trie.pxd file from the previous post generates the following AST, which is schematically shown below (we leave off most leaves for presentation purposes):
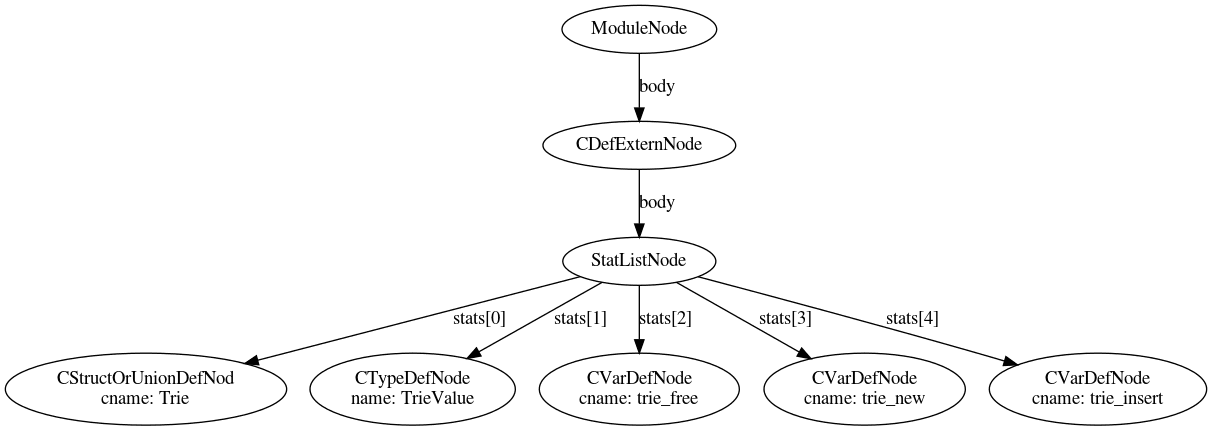
Pxd Visitor
We implement a Pxd Visitor object following the protocol defined in Cython. In particular, our PxdVisitor implements a visit method for every type of node in the AST. For instance
def visit_CStructOrUnionDefNode(self, node):
# extract info from node
return self.visitchildren(node)
visits the CStructOrUnionDef type node in the AST representing a union or struct declarations.
def visit_CTypeDefNode(self, node):
# extract info from node
return self.visitchildren(node)
visits ctypedefs and so on.
Our Visitor class walks all the nodes in the tree and collects information that we need to build the corresponding Python wrapper classes and functions. For a given struct (in our example the Trie struct), the visitor collects all the C functions that will become Python class methods. These are identified by the fact that their names match the name of the struct. For example, trie_new and trie_insert are functions for creating Trie structs and inserting data into them respectively.
Once all the C functions are mapped to their corresponding structs, the Python classes can be built using string templates along with functions for managing type conversions between Python and C. We will explore this approach below.
Python Class Lifetime Management
The C structs defined in the pxd files should be wrapped by Python classes, as these are the closest language equivalent. Ideally, the Python classes will manage the lifetime of the corresponding C struct. This means that the C struct will be created when the Python class is created and it will be destroyed and its memory released when the Python class is destroyed. In this way, the C struct is "buried under the hood", so the speak, and the user of the Python class is essentially oblivious to its existence.
For our trie example, the Python wrapper class looks like the following:
cimport _trie
cdef class Trie:
cdef _trie.Trie* _this_ptr
def __cinit__(self):
self._this_ptr = _trie.trie_new()
if self._this_ptr is NULL:
raise MemoryError()
def __dealloc__(self):
if self._this_ptr is not NULL:
_trie.trie_free(self._this_ptr)
This ensures that the lifetime of the underlying C Trie struct is tied to the lifetime of the Python Trie class.
Wrapping Functions
Wrapping C functions is simple in principle. The idea is to cast the Python objects from the function signature into their nearest C equivalent type, then call the underlying C function via the classes' internal pointer and finally convert any returned C objects back to Python types. Wrapping functions is essentially an exercise in managing type conversions between C and Python.
However, in practice, this can be a difficult task for a compiler to achieve. For instance, in our Trie example the insert method has the following C signature
int trie_insert(Trie *trie, char *key, TrieValue value);
The Trie *trie can be replaced with self.this_ptr. The char* key argument can be replaced with a Python string (more on this below). TrieValue is a typedef of void*, which is C approach to generic programming. From the Python side, we have a few choices in terms preserving this generacy.
One approach would be to declare value to be a generic Python type object and then attempt to cast it to a <void*> in the C function call, i.e.
def insert(self, ..., object value);
return<int> _trie.trie_insert(self.this_ptr, ..., <void*>value)
However this could easily fail if the user passed in a nonsensical value object.
The other approach, as advocated by the Cython documentation, is to specify a concrete type in the Python function call, for instance, int or double. This breaks type generacy but prevents runtime errors.
Interestingly, this is also the approach used by autowrap to handle C++ templates. In autowrap, the user can specify the concrete Python type they wish to implement using a compiler directive. This eases the burdon of having to implement highly redundant Python classes for every concrete Python type one wishes to use. I may implement a compiler directive like this at some point in the future.
As for the char * in the C function, exposing a Python str (unicode in Python 3) is thoroughly in the Cython documentation. We just implement the type conversion directly.
So a naive Python wrapper would look like the following1
def insert(self, str key, int value):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
return self._this_ptr.trie_insert(Trie *trie, c_key, <void *>value)
There is one more problem with this approach, namely that the returned int is not really meant to be an integer, per se. It's an int from a C function call indicating failure by a 0 and success by a positive value. This is one of C's (limited) approach to runtime error handling. Clearly, a parser just looking at the pxd return type cannot distinguish between an int of this type and a regular int.
Cython provides an alternative type, bint, as in binary int, that can be used for these types of function calls. A bint auto-converts to a Python bool instead of an int. So for our pxd parser to pick it up, we would have to manually update our pxd file from
int trie_insert(Trie *trie, char *key, TrieValue value);
to
bint trie_insert(Trie *trie, char *key, TrieValue value);
The returned bint's value should be checked and an exception should be raised if it is false. So am improved wrapper look like the following
def insert(self, str key, int value):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
if not _trie.trie_insert(self._thisptr, c_key, <void *>value):
raise MemoryError()
Python Protocols and Special Methods
As an easier wrapping example, the length of the trie struct can be determined via the following function
unsigned int trie_num_entries(Trie *trie);
Our python wrapper is simply
def num_enties(self):
return _trie.trie_num_entries(self._this_ptr)
Clearly, Python users would expect a __len__() special method instead of num_entries(). We can either allow users to adjust the function name manually after generating the pyx file or directly map num_enties to __len__ in the pxd parser. We'll use a direct mapping for now but it's by no means a general solution.
So our length method would look like the following
def __len__(self):
return _trie.trie_num_entries(self._this_ptr)
This problem can emerge for any C functions that implements Python protocol functionality, such as __get__(), __set__(), __getitem__(key), __setitem__(key, value), etc.
Handling Includes
Includes should be one of the simple aspects of the parser. However, there is one subtlety that needs to be addressed. In particular, Cython has a convention whereby for any pyx file, say foo.pyx, all C declarations from a pxd file with the same name, e.g. foo.pxd, are automatically included at compile time. This can cause a name collision if we wish to give our Python classes and functions the same name in Python as they have in the underlying C library.
One approach to avoiding name collisions is to first name the pxd file _foo.pxd (add a leading underscore) to prevent it from being automatically included in foo.pyx. Then rename the imported C declarations with a leading underscore in the pyx file.
This will prevent C and Python names from colliding in the pyx file.
Putting it All Together
So, running our pyx generator and manually replacing void* and bint we get the following Python wrapper class
cimport trie
cdef class Trie:
cdef trie.Trie* _this_ptr
def __cinit__(self, ):
self._this_ptr = trie.trie_new()
if self._this_ptr is NULL:
raise MemoryError()
def __dealloc__(self):
if self._this_ptr is not NULL:
trie.trie_free(self._this_ptr)
cdef insert(self, str key, int value):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
if not trie.trie_insert(self._thisptr, c_key, <void*>value):
raise MemoryError()
cdef insert_binary(self, str key, int key_length, int value):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
if not trie.trie_insert(self._thisptr, c_key, <void*>value):
raise MemoryError()
cdef lookup(self, str key):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
return <int>trie.trie_lookup(self._this_ptr, c_key)
cdef lookup_binary(self, str key, int key_length):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
return <int>trie.trie_lookup_binary(self._this_ptr, c_key, <int>key_length)
cdef remove(self, str key):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
return <int>trie.trie_remove(self._this_ptr, c_key)
cdef remove_binary(self, str key, int key_length):
py_byte_str = key.encode('UTF-8')
cdef char* c_key = py_byte_str
return <int>trie.trie_remove_binary(self._this_ptr, c_key, <int>key_length)
cdef __len__(self):
return <int>trie.trie_num_entries(self._this_ptr)
Final Words
There's much more work to do on the pxy generator. For instance, the following items still need to be handled
- Enums
- Compiler directives
- Comments
- More special function mapping
- Exception Handling
In my next post, I will revisit this process for C++. In particular, I'll use libClang to parse C++ header files along with autowrap for Pyx generation. See you next time.
Footnotes
See Cython's documentation on the need for the temporary
py_byte_strobject ↩